Project Structure¶
This is the class structure diagram that Hermione relies on:
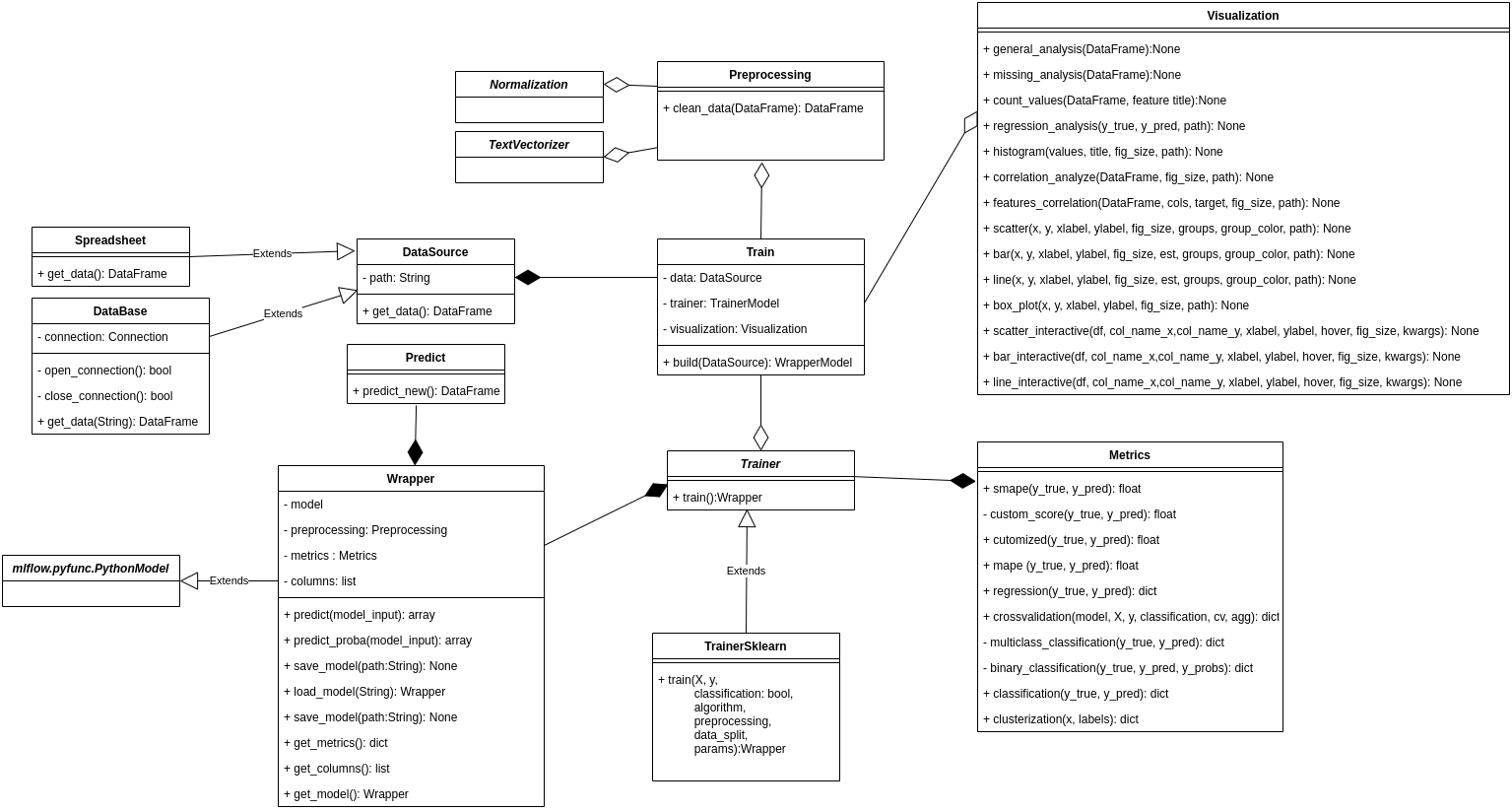
Here we describe briefly what each class is doing:
Data Source¶
DataBase - should be used when data recovery requires a connection to a database. Contains methods for opening and closing a connection.
Spreadsheet - should be used when data recovery is in spreadsheets/text files. All aggregation of the bases to generate a “flat table” should be performed in this class.
DataSource - abstract class which DataBase and Spreadsheet inherit from.
Preprocessing¶
Preprocessing - concentrates all preprocessing steps that must be performed on the data before the model is trained.
Normalization - applies normalization and denormalization to reported columns. This class contains the following normalization algorithms already implemented: StandardScaler e MinMaxScaler.
TextVectorizer - transforms text into vector. Implemented methods: Bag of words, TF_IDF, Embedding: mean, median e indexing.
Visualization¶
Visualization - methods for data visualization. There are methods to make static and interactive plots.
App Streamlit - streamlit example consuming Titanic dataset, including pandas profilling.
Model¶
Trainer - module that centralizes training algorithms classes. Algorithms from
scikit-learnlibrary, for instance, can be easily used with the TrainerSklearn implemented class.Wrapper - centralizes the trained model with its metrics. This class has built-in integration with MLFlow.
Metrics - it contains key metrics that are calculated when models are trained. Classification, regression and clustering metrics are already implemented.
Tests¶
test_project - module for unit testing.